Rethinking RAGs: How OpenAI's Direct Support Changes the Game
I'm Brian Yang, a founder with a successful exit and extensive software experience. With a passion for creative thinking and problem-solving, I've enjoyed a journey from large companies such as Google, Meta, and LinkedIn to becoming an entrepreneur and investor. Through each challenge, I've learned to persevere and grow both personally and professionally.
Some of my career highlights include:
- Cofounded a company in 2017 as CTO which eventually exited to the NASDAQ [DGHI] with a peak valuation of $250 million
- Starting a venture in 2021 as the Executive Chairman and sole initial investor with a peak valuation of $64 million
- Built multiple large scale datacenters, totaling over 100 MW of electrical capacity.
- Working on the hardest engineering problems at LinkedIn, Meta, and Google
- Closed a $3 million non-dilutive debt financing round
- Scaled a company from just myself to 7 executives, 1 director, 3 employees, and over 10 contractors in 6 months
- Scaled a personal engineering team to 9 engineers in 2 months

What is a RAG?
"RAG" typically stands for "Retrieval-Augmented Generation." This is a methodology for enhancing the output of language models by combining them with an external knowledge retrieval mechanism. Here's a breakdown of how RAG works:
Retrieval: The model retrieves relevant documents or pieces of information from a large corpus or database. This is often based on the input query to provide contextually relevant data.
Augmented: The retrieved information is then used to augment the language model's knowledge. This step helps the model to incorporate or reference information that may not be within its pre-trained knowledge base.
Generation: With the augmented information, the language model generates a response or continuation that is informed by the additional context.
RAG models are particularly useful for ensuring that the responses generated by a language model are up-to-date and factual, as the model has access to external, current information that might not have been included in its original training data.
RAGs typically use a vector store to store embeddings. Embeddings are the semantic representation of a word or phrase. For example, a dog and a cat would be closer in the embedding vector space than a dog and an airplane.
OpenAI's Support of RAGs
![]()
As of 11/6 during OpenAI's developer conference, they announced the Assistants API. https://platform.openai.com/docs/assistants/overview
Notably, developers can connect an OpenAI-managed embedding store to their assistant, essentially bypassing the need for the retrieval and augmentation step. Furthermore, OpenAI's Assistants API is a stateful API, meaning that memory management is no longer necessary.
Is building your own RAG obsolete? Not quite.
Current gaps in OpenAI's retrieval process
The current offering from OpenAI sounds great. You get the following out of the box:
A memory system
A managed vector store with automatic chunk sizing and embed generation
Retrieval and augmentation of your prompt
Each of these components requires fairly deep specific domain knowledge. What's wrong with using this system directly?
There are important considerations that might not make this system suitable for every problem.
The Key Problem - Embeddings
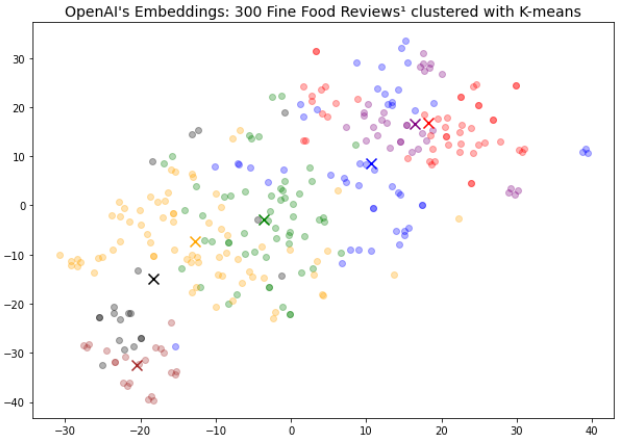
Here is where we run into the first problem. In theory, everything is great - you get everything managed for you and you just need to build your application, right?
Here is where it might not be that simple.
Imagine you're building an enterprise RAG system for a specific company. You put all of the documents into the Assistant's API and you ask it for an answer. But... it's inconsistent. Sometimes it works, sometimes it doesn't. What gives?
OpenAI's embeddings are trained on the open web. It doesn't understand any internal jargon or terms that your documents or conversations have. For example, "Project Cambria" was the name of Meta's new VR device internally but externally it was known as the "Meta Quest Pro". OpenAI's embedding system would have no way of understanding "Project Cambria" and its relation to VR.
Previously, you would be able to finetune the embeddings to understand the semantics of your internal corpus of data, but unfortunately, that isn't possible in this case. This means you're unfortunately stuck with lower recall for your chunks and therefore low accuracy.
The next key problem - the vector store itself
When you ingest data into your vector store, you usually do a fair amount of data massaging. Multiple processes filter out noisy data, especially from data sources that are typically noisy such as a group chat. Afterward, you index the data based on several attributes that you want to search for. For example, creation date, group chat name, and members are all reasonable indices to add. Finally, you test your system by querying it and seeing how it performs.
However, there is no way of doing a query where we filter the knowledge only on data from a specific group chat during a specific period. In fact, the file returned seems to lack any metadata at all.
https://platform.openai.com/docs/assistants/tools/knowledge-retrieval
The final problem - control of your data
While this is less of a technical problem and more of a business issue, it would be risky to upload your entire corpus of data into OpenAI. While OpenAI has promised not to train on your data, giving custody of key data is generally a non-starter for companies with strict data protection policies.
